
how to do agentic evals
what building an eval system for conversational agents actually required
When your agent schedules an interview, sends a message to a candidate, or updates an application status, you can’t evaluate it the way you test a function. The agent changes the world and testing whether it changed the world correctly means building a world where it can safely do that.
Standard evals don’t solve this. Static test environments miss how agents behave when conditions shift. Single runs miss non-determinism, even at temperature 0. Single-turn tests miss the performance drop when conversations go multi-turn.
In January, Anthropic published Demystifying Evals for AI Agents. I like their engineering posts, and this one gives a solid overview: terminology, grader types, an implementation roadmap. This article goes deeper into one corner: building the eval system for conversational agents that take real actions. Previously I wrote about why model capability doesn’t translate to agent reliability. This article is about what it takes to get there.
evals
When most people say “evals,” they mean a unit test for model behavior: give it an input, check the output. The checking can be deterministic, such as string matching or a rule. Or you can point another LLM, often called a judge, at the output and ask whether it’s close enough to the expected answer. Platforms like Langfuse and Pydantic Logfire offer this as a playground: see a completion, tweak the input prompt, compare outputs.
We run these too. We use them to test safety: send a hundred off-topic or dangerous messages (politics, religion, protected characteristics) and verify the agent redirects every one. We use them to test FAQ accuracy: clients define how the agent should answer specific topics, and the eval tests whether it does across different phrasings. We use them to iterate on prompts: change the prompt, run the same batch, compare what changed in the completions.
These evals are useful, but they evaluate the surface. They tell you what the agent said, but agent might lie. An agent can say “your interview is confirmed for tomorrow” and sound perfectly helpful, while no interview was ever scheduled in the database. An agent that takes actions across multiple turns, changes state, and reasons internally about what to do next needs deeper instruments.
the harness
To know whether the agent actually scheduled that interview, you need to run it in a world where it can take actions safely. Not a mock, not a stub: a world that behaves like production without being production. That means the agent must run its full production logic. If you mock the agent, you’re not testing the agent. If you mock the world too aggressively, you’re testing behavior in a world that doesn’t exist.
The agent doesn’t need to know it’s being tested. As long as the interfaces behave the same way, it doesn’t matter what’s behind them. A recent paper on agent evaluation calls this the contract principle: correctness is defined by the interface, not the implementation. Swap the providers: messages go to memory instead of the real messaging service, external API calls hit mocks that honor the same contracts, time is injected so the agent perceives the correct historical moment.
The harness should never run in production, but the data inside it should be as close to production as possible. That can mean exporting real context from production, enough for the agent to behave correctly, with all PII stripped. Or it can mean generating synthetic scenarios that are realistic enough to surface the same failures real users would. Either way, what the agent sees inside the harness should be indistinguishable from what it sees in production. Save this data as a frozen template: the starting scenario, the user, their conversation history, everything the agent needs as context.
Once you have a template, you need to make sure each run starts clean. If the agent schedules an interview during one run, the next run can’t start with that interview already on the calendar. For each eval run, you clone the template into a disposable copy. The agent mutates the clone freely, and the clone is discarded after. Run it ten times, and all ten start from the same state.
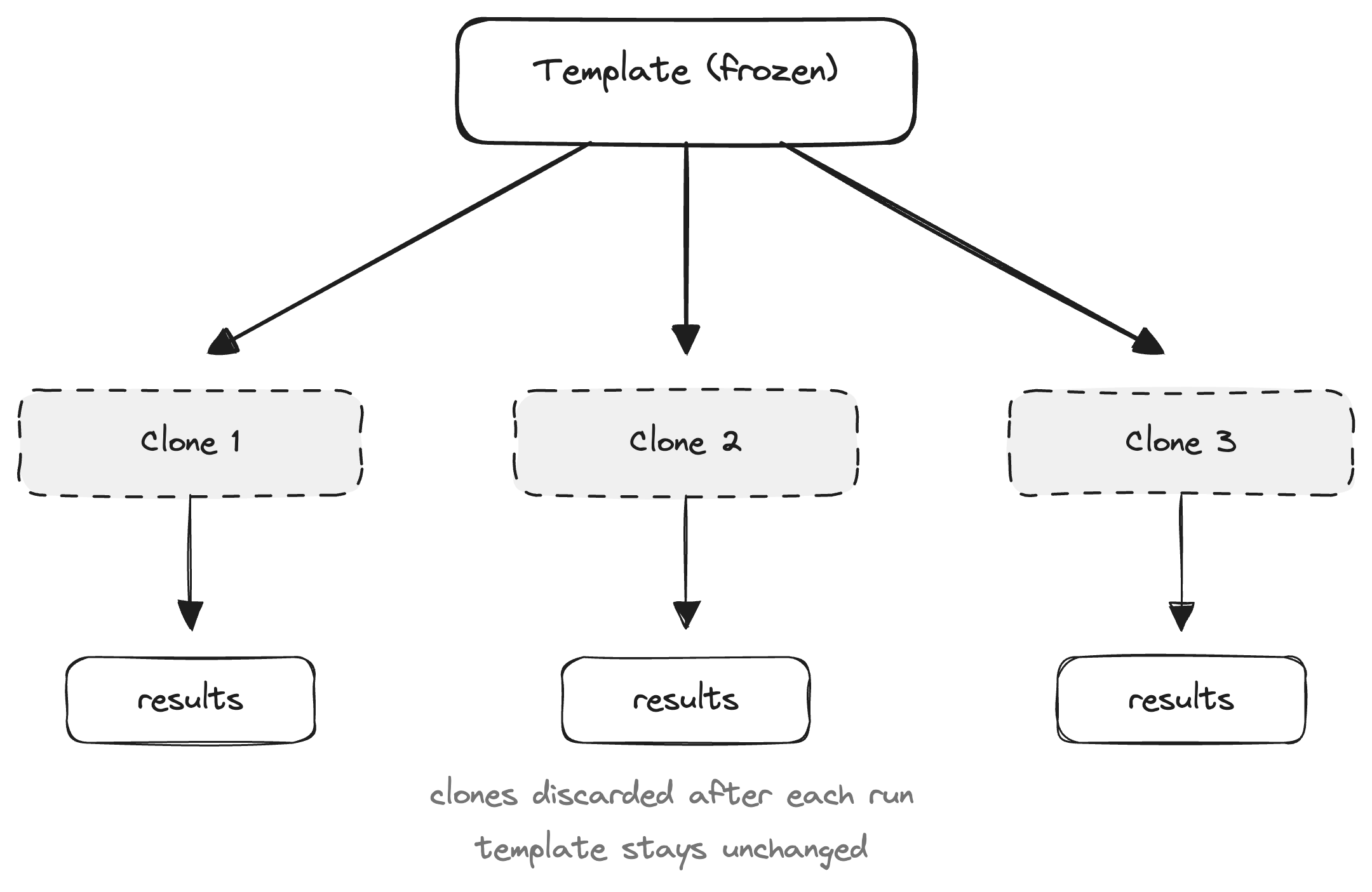
If your agent has time-dependent logic, each clone also needs the correct historical moment injected. An agent making scheduling decisions needs to think it’s March 3rd at 2pm, not whenever the eval runs. And anything that would reach the outside world, notifications, webhooks, downstream processes, must be suppressed. Otherwise an eval run could send a real message or trigger a real workflow. If you run evals concurrently, each run also needs its own isolated providers so one run’s state doesn’t leak into another.
Anthropic’s guide describes all of the above in one bullet: “build a robust eval harness.” In practice, it’s the most engineering-intensive part of the whole system. Once it exists, it unlocks deeper eval modes.
replay
The simplest thing you can do with the harness is replay a situation. Take a specific moment, a user, a message, the state around it, freeze it as a template, and run the agent against it. Did it do the right thing?
Now run it 3, 5, 8 times. Agents are non-deterministic, so running the same situation repeatedly is how you distinguish reliability from luck. Did the agent succeed at least once? That’s pass@k. Did it succeed every single time? That’s pass^k. For reliable agents in production, pass^k is what we should worry about.
I did this when testing role coherence under adversarial pressure: freeze a conversation turn, replay it fifty times, observe the variance. The same principle applies broadly. It works for failures and for happy paths. A passing result that holds across every run is a pattern you can trust. A failure that repeats is a pattern you can fix.
Replay is a simple and important tool for testing reliability under a specific situation. But real users don’t send one message and stop. They have a conversation.
simulation
Simulation is a full multi-turn conversation where an LLM plays the user. The simulated user needs a persona, a scenario, and a goal. A study from Microsoft and Salesforce Research tested 15 models across over 200,000 simulated conversations and found that performance drops from around 90% in single-turn to 65% in multi-turn, a 25-point gap consistent from small open-source models to frontier. When LLMs take a wrong turn, they don’t recover. Simulation is how you test whether your agent does.
The simulated user’s persona matters as much as the task. Researchers at Collinear AI found 2 to 30% performance degradation when they varied user traits: impatience, incoherence, skepticism. Standard benchmarks use cooperative, patient users, but real users are often neither. An eager user surfaces different failures than a skeptical one.
Where do the scenarios come from? When I tested role coherence with Promptfoo, the red-teaming tool generated attack scenarios from a description of the agent’s purpose. There are many commercial platforms that offer generation of simulation scenarios using your agent’s system prompt as input. Frankly, you can achieve same or more with any reasoning model by providing the full picture: system prompt, tool definitions, domain context, and the specific constraints your agent operates under.
The goal of simulation can be structured or open-ended. A simulated user can take the conversation in directions no test script would. Fully open-ended simulation is the ideal, but in practice most systems sit somewhere in between: scenarios are predefined, personas configured in advance, evaluation against an expected outcome. Our agents operate in a bounded domain with defined goals and a constrained conversation space. If yours do too, structured simulation with varied personas covers most of what you need to test. What it won’t catch is what falls outside your scenario set, and pushing toward more open-ended exploration over time is the right direction.
the judge
Just as an agent in production should leave traces you can review, so should an agent in the harness. Not only the conversation, but how it changed the world and what it was thinking when it did.
Capture the full state before and after each run, and diff them. A recent paper calls these state-diff contracts. The diff is your ground truth: what actually changed, and what changed that shouldn’t have. Some of this you can verify deterministically, without an LLM: was the status updated, was the event created, does the diff match what was expected? That’s the most reliable evaluation you can build.
For more complex outcomes, you need a judge. The standard approach, LLM-as-a-Judge, gives an LLM the conversation and asks it to score. But that’s evaluating the final result without seeing how the agent got there. A Meta and KAUST research group proposed Agent-as-a-Judge: give the evaluator the intermediate reasoning and the state changes, not only the conversation. They found 90% alignment with human consensus, versus 70% without. We do the same. The more context the judge has, the better it evaluates.
the flywheel
The judge evaluates a simulation run and reveals a failure. You see the state diff, you see the reasoning. Now what?
Promote that failure to a template. Trim the conversation to the critical turn, freeze the state. Now you can replay that exact situation with repetitions to confirm whether the failure is a pattern or a one-off. If it’s a pattern, you fix it. After you fix it, the template stays. It becomes a regression test: every future change to the agent can be tested against this situation.
This is how the system compounds: simulation discovers failures, the judge and human review explain them, and replay locks them down.
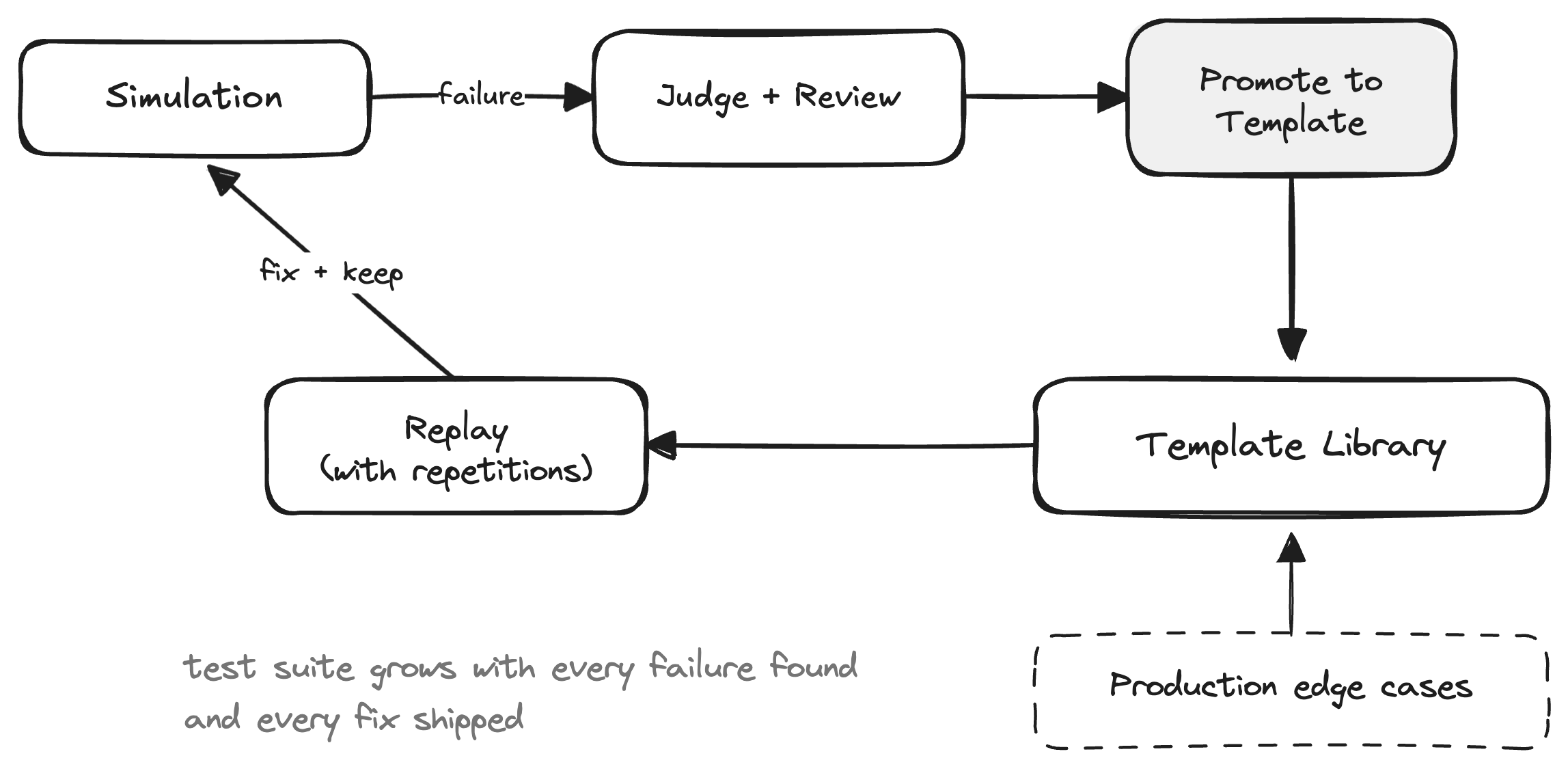
Over time, the library of situations your agent must handle grows with every failure you find and every fix you ship. Now you have the tools to ship reliably.